In our recent paper, we present CleanUNet, a causal speech denoising model on the raw waveform. The following are the key highlights of our work:
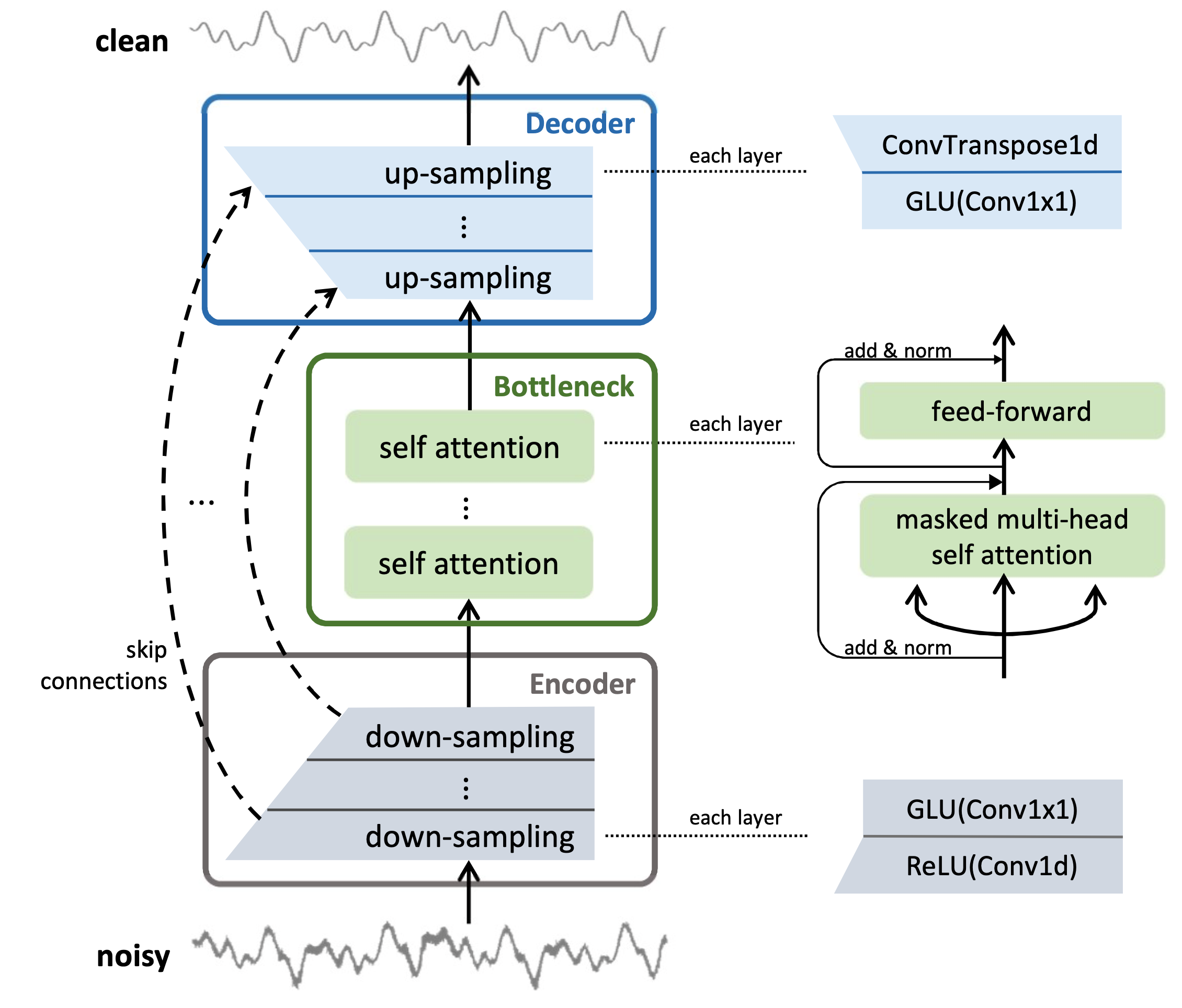
The proposed model is based on an encoder-decoder U-Net architecture combined with several self-attention blocks to refine its bottleneck representations, which is crucial to obtain good results.
The model is optimized through a set of losses defined over both waveform and multi-resolution STFT. We find that soley minizing the high-band STFT loss with waveform loss will improve the human percetual quality of denoised audio.
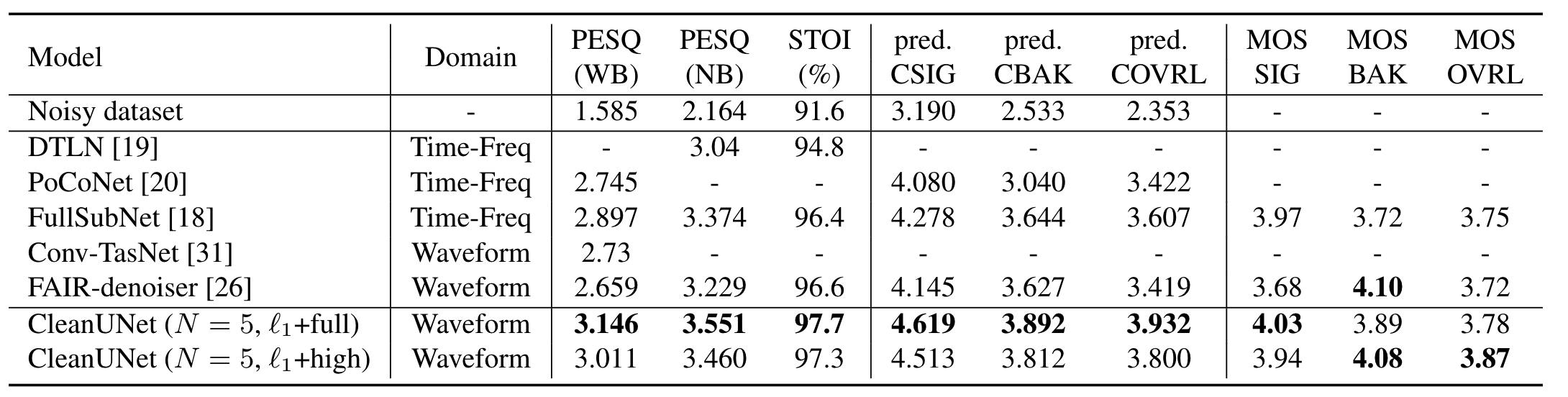
The proposed method outperforms the state-of-the-art models in terms of denoised speech quality from various objective and subjective evaluation metrics.
Method
Below diagram illustrates the CleanUNet architecture: It contains an encoder, a decoder, and a bottleneck between them. The encoder and decoder have the same number of causal convolutional layers, and are connected via skip connections (identity maps). The bottleneck is composed of N self-attention blocks. Each self-attention block is composed of a multi-head self attention layer and a position-wise fully connected layer. Each multi-head self-attention layer has 8 heads, model dimension 512, and the attention map is masked to ensure causality.
We optimize a loss function defined as a combination of l1 waveform loss and multi-resolution STFT (M-STFT) loss. In practice, we find the full-band M-STFT loss sometimes leads to low-frequency noises on the silence part of denoised speech, which deteriorates the human listening test. On the other hand, if our model is trained with l1 waveform loss, the silence part of the output is clean, but the high-frequency bands are less accurate than the model trained with the M-STFT loss. This motivated us to define a high-band M-STFT loss, which only compute the loss on high-frequency band (i.e., 4kHz to 8kHz for 16kHz audio).
Results
Objective and subjective evaluation results for denoising on the DNS (2020)
Denoised Samples
Keyboard / Mechanical noise:
Noisy
CleanUNet
FAIR-denoiser
Clean
FullSubNet
Dog barking:
Noisy
CleanUNet
FAIR-denoiser
Clean
FullSubNet
Human talking:
Noisy
CleanUNet
FAIR-denoiser
Clean
FullSubNet
Indoor noise:
Noisy
CleanUNet
FAIR-denoiser
Clean
FullSubNet
Street noise:
Noisy
CleanUNet
FAIR-denoiser
Clean
FullSubNet
Shrill noise:
Noisy
CleanUNet
FAIR-denoiser
Clean
FullSubNet
Wind noise:
Noisy
CleanUNet
FAIR-denoiser
Clean
FullSubNet
Citation
@inproceedings{kong2022speech,
title={Speech Denoising in the Waveform Domain with Self-Attention},
author={Zhifeng Kong and Wei Ping and Ambrish Dantrey and Bryan Catanzaro},
booktitle={ICASSP},
year={2022},
}