Long-Short Transformer: Efficient Transformers for Language and Vision
Published:
Author: Chen Zhu, Wei Ping, Chaowei Xiao, Mohammad Shoeybi, Tom Goldstein, Anima Anandkumar, Bryan Catanzaro
Posted: Wei Ping
Transformers have achieved success in both language and vision domains. However, it is prohibitively expensive to scale them to long sequences such as long documents or high-resolution images, because self-attention mechanism has quadratic time and memory complexities with respect to the input sequence length.
In our recent paper, we propose Long-Short Transformer (Transformer-LS): an efficient self-attention mechanism for modeling long sequences with linear complexity for both language and vision tasks. Transformer-LS aggregates a novel long-range attention with dynamic projection to model distant correlations and a short-term attention to capture fine-grained local correlations. It can be applied to both autoregressive and bidirectional models without additional complexity. Transformer-LS outperforms the state-of-the-art transformer models on multiple tasks in language and vision domains, including the Long-Range Arena benchmark, autoregressive language modeling, and ImageNet classification.
Code for training and inference, along with pretrained models, is available on our Github repository.
Method
Long-Short Transformer (Transformer-LS) integrates a dynamic projection based attention to model long-range correlations, and a sliding window attention to capture fine-grained correlations. See Figure 1 for an illustration.
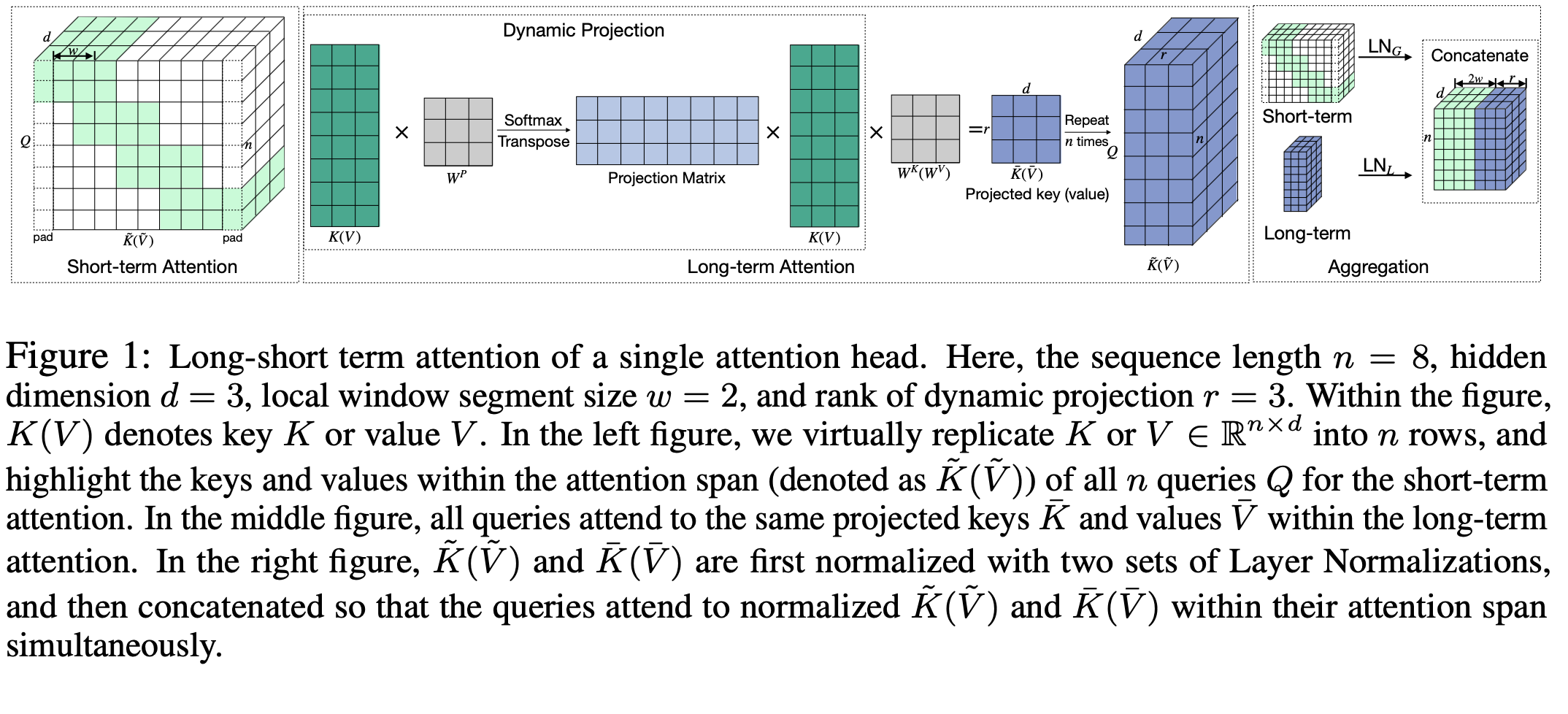
We compute a dynamic low-rank projection to form a low resolution representation of the input sequence, which depends on the content of the input sequence. Then, it allows each token to attend to the entire input sequence. In contrast to previous low-rank projection methods, our dynamic projection method is more flexible and robust to semantic-preserving positional variations (e.g., insertion, paraphrasing). We demonstrate that it outperforms previous low-rank methods on Long Range Arena benchmark.
Vanilla implementation of sliding window attention (e.g., attention mask) won't reduce the quadratic complexity. We use the simple yet effective segment-wise sliding window attention to capture fine-grained local correlations. Specifically, we divide the input sequence into disjoint segments with length w for efficiency reason. All tokens within a segment attend to all tokens within its home segment, as well as w/2 consecutive tokens on the left and right side of its home segment, resulting in an attention span over a total of 2w key-value pairs. See Figure 2 for an illustration.

We find a scale mismatch problem between the embeddings from the long-range dynamic projection based attention and short-term sliding window attentions. As a result, we design a simple but effective dual normalization strategy, termed DualLN, to account for the mismatch and enhance the effectiveness of the aggregation.
Building on these key ingredients, our Transformer-LS outperforms the state-of-the-art transformer models on various tasks in language and vision domains. One can find the results in the following section and more details in paper.
Results
Long-Range Arena
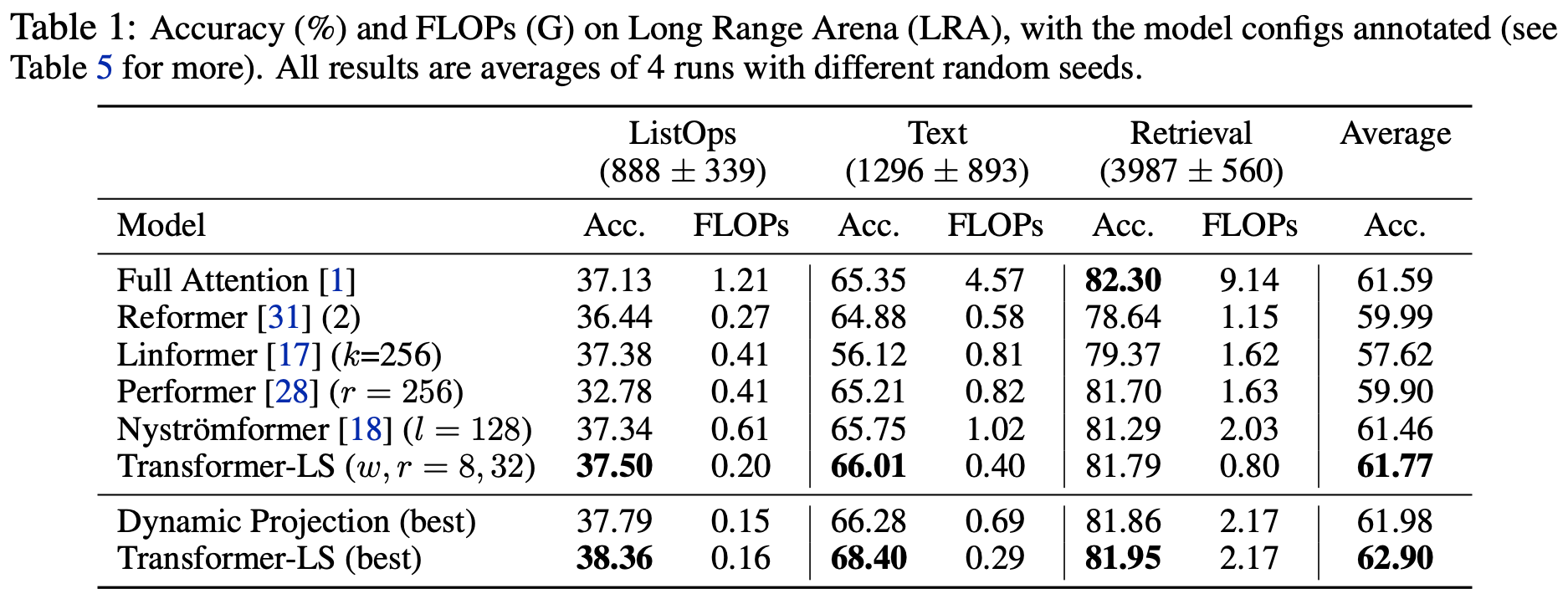
Autoregressive Language Modeling
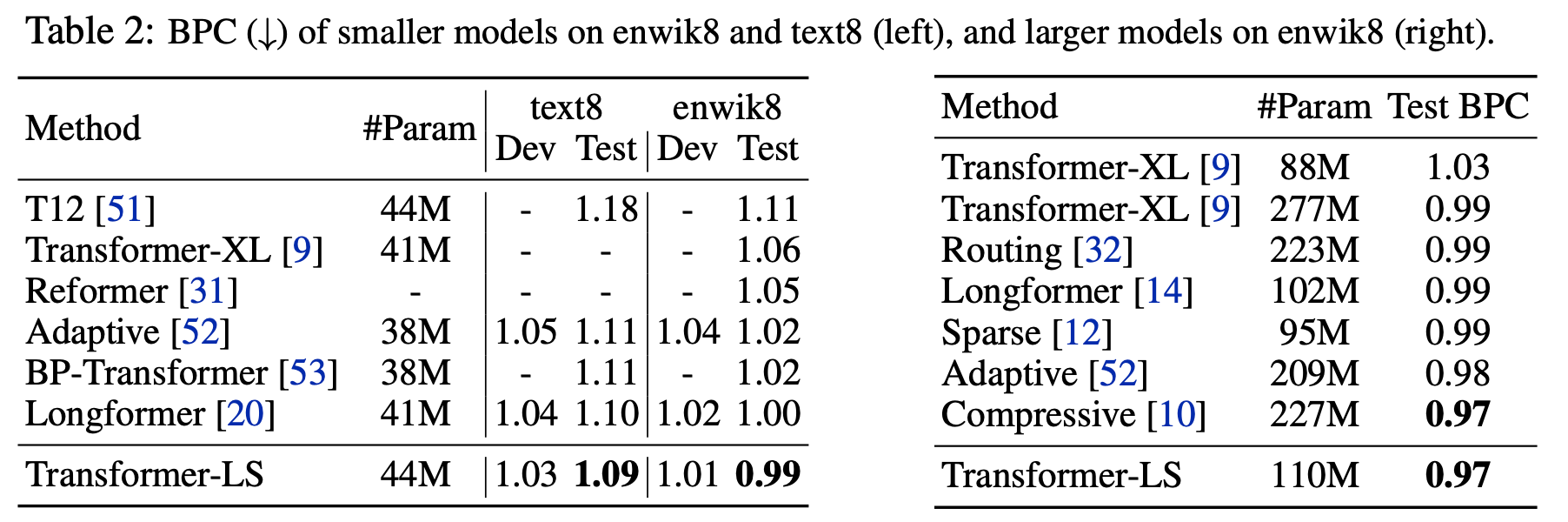
ImageNet Classification