
RAD-TTS: Parallel Flow-Based TTS with Robust Alignment Learning and Diverse Synthesis
Published:
![]()
Kevin Shih, Rafael Valle, Rohan Badlani, Adrian Lancucki, Wei Ping and Bryan Catanzaro
In our recent paper, we propose RAD-TTS: a parallel flow-based generative network for text-to-speech synthesis. It extends prior parallel approaches by additionally modeling speech rhythm as a separate generative distribution to facilitate variable token duration during inference. We further propose a robust framework for the on-line extraction of speech-text alignments: a critical yet highly unstable learning problem in end-to-end TTS frameworks. Our experiments demonstrate that our proposed techniques yield improved alignment quality, better output diversity compared to controlled baselines.
RAD-TTS is trained by maximizing the likelihood of the training data, which makes the training procedure simple and stable. We additionally use an unsupervised alignment learning objective that maximizes the likelihood of text given mels. This additional objective allows us to learn speech text alignments online as the RAD-TTS model trains.
An important contribution of our work is generative modelling of these durations, instead of deterministic regression models that most non-autoregressive TTS models currently use. Utilizing a normalizing flow for duration modelling allows us to resolve the output diversity issue in parallel TTS architectures.
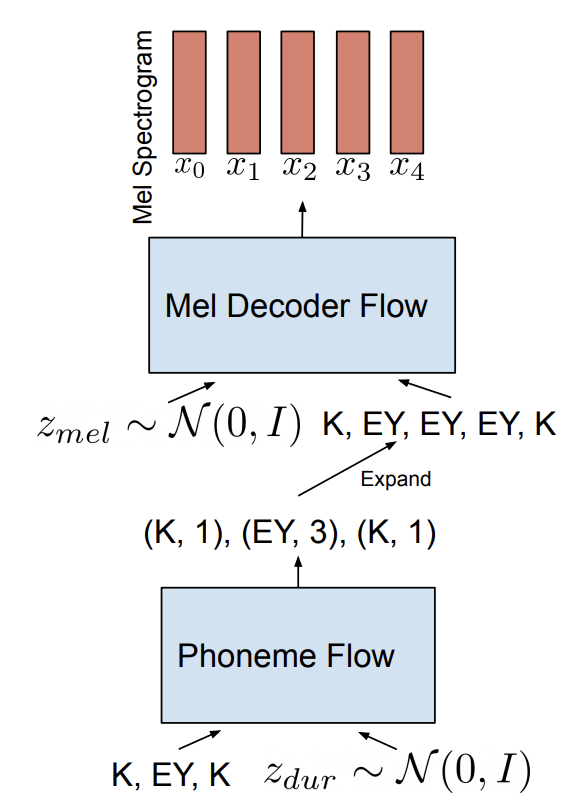
Following diagram summarizes the inference pipeline for RAD-TTS. The duration normalizing flow first samples the phoneme durations which are then used to prepare the input to the parallel Mel-Decoder flow.
The RADTTS model can help voice automated customer service lines for banks and retailers, bring video-game or book characters to life, and provide real-time speech synthesis for digital avatars.
Developers and creators can utilize RAD-TTS for expressive speech synthesis to generate voices for characters, virtual assistants and personalized avatars. NVIDIA’s in-house creative team even uses the technology to produce expressive narration for a video series on the power of AI. Here’s our researchers explaining the applications of this technology:
The RAD-TTS speech synthesis is extremely fast and can be utilized for expressive speech synthesis in many Real Time applications. At Real Time Live event during SIGGRAPH 2021, we presented the application of RAD-TTS model in video-conferencing, story-telling and virtual assistants. Following is the video of the real-time demo during SIGGRAPH:
Below we provide samples produced with RAD-TTS for mel-spectrogram synthesis and WaveGlow for waveform synthesis.
1. Mean Opinion Score Comparison
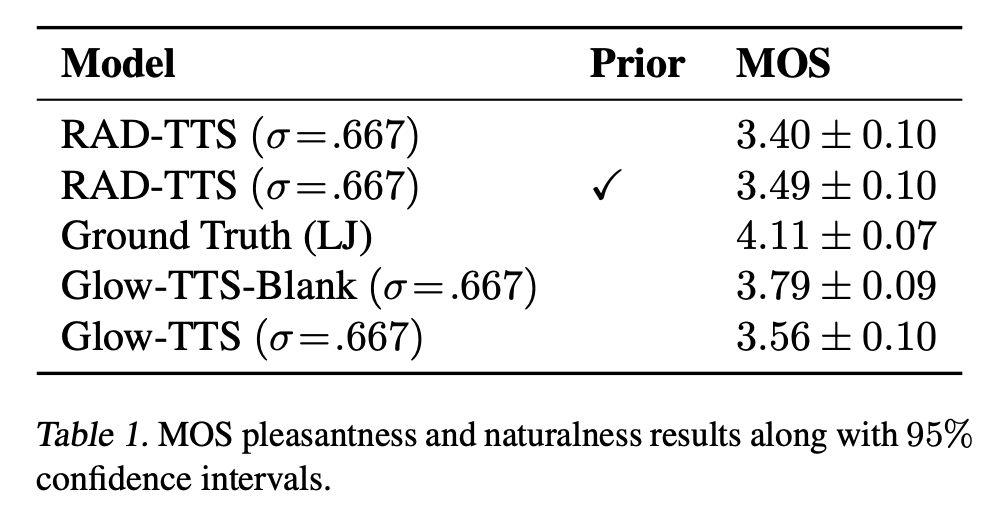
| LJSpeech Ground Truth | RAD-TTS with prior(σ²=0.667) | GlowTTS w/ blanks |
|---|---|---|
2. Diversity in samples generated
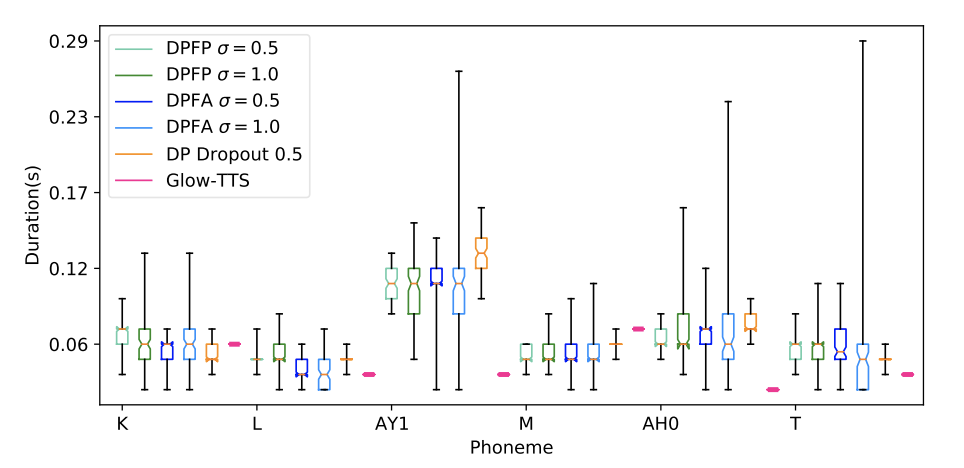
Phoneme-level duration distributions for the word Climate with 95% confidence intervals obtained from 100 samples collected from different models conditioned on the phrase 'Climate change knows no borders'. Explicit generative models (shades of green and blue) provide high diversity in speech rhythm by adjusting σ, whereas test-time dropout (yellow) provides limited variability.
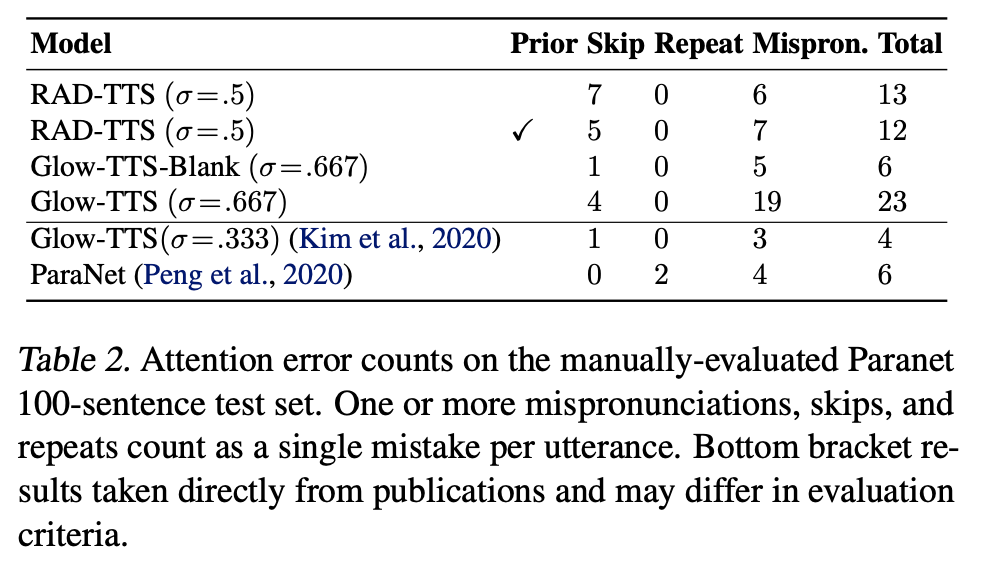
3. Online Alignment Learning Algorithm
4. RAD-TTS++ : explicitly conditioning RAD-TTS decoder on f0 (pitch) and energy
The following are some samples from RAD-TTS++, in which we use a discriminative model to predict f0 (pitch) and energy and condition the decoder on the predicted f0, energy. The following is a RAD-TTS++ synthesized sample from a speaker in our dataset:
We also train our RAD-TTS++ model on speaker from the Blizzard Challenge and following is a synthesized samples for a speaker from Blizzard Challenge:
This conditioning of f0 and energy allows us to make any speaker sing or rap songs. Here's a rap sample from RAD-TTS where we make one of RAD-TTS++ speaker rap a song by explicitly conditioning on f0 and energy from the ground truth 'The Real Slim Shady' rap song by Eminem.
In the following samples, we take Etta James' song 'At Last' and make one of RAD-TTS++ speakers sing the same song. We then overlay the original and synthesized audio to generate a duet for them!
Implementation details
Code for training and inference, along with pretrained models on LJS, will be released soon.
Citation
@inproceedings{
shih2021radtts,
title={RAD-TTS: Parallel Flow-Based {TTS} with Robust Alignment Learning and Diverse Synthesis},
author={Kevin J. Shih and Rafael Valle and Rohan Badlani and Adrian Lancucki and Wei Ping and Bryan Catanzaro},
booktitle={ICML Workshop on Invertible Neural Networks, Normalizing Flows, and Explicit Likelihood Models},
year={2021},
url={https://openreview.net/forum?id=0NQwnnwAORi}
}